В предыдущей статье я описывал мета-скиллы — особые скиллы, задача которых — создавать, оценивать и улучшать другие скиллы. Это инструменты, которые берут на себя тяжёлую работу по самосовершенствованию: анализируют вашу обратную связь, оценивают качество скиллов и обновляют инструкции к ним — чтобы вам не приходилось писать их вручную.
Но одних инструментов недостаточно. Нужен процесс — персонализированный набор рабочих потоков с вашим участием (workflows), который гарантирует, что самоизменения агента приводят к улучшениям, а не к деградации качества.
Эта статья — о таком процессе. Опираясь на принципы Scrum — Прозрачность, Инспекция и Адаптация — она описывает, как выстроить цикл решения задач и цикл улучшения скиллов.
В чем проблема — на примере
Представьте: вы продакт-менеджер, который регулярно анализирует конкурентов и рыночные тренды, улучшая позиционирование продукта и стратегию на основе исследований. Вы создали несколько скиллов агента для этих задач, например:
- скилл для получения публичных сигналов — например, изменений в списках фич у конкурентов,
- скилл для улучшения позиционирования продукта на основе конкурентного анализа,
- скилл для поиска отраслевых новостей и структурирования их в виде рыночных трендов,
- скилл для создания отформатированных сводок и сравнительных таблиц из всех найденных данных и передачи их во внутреннюю базу знаний компании.
Результаты работы этих скиллов далеки от совершенства, поэтому вы постоянно их дорабатываете. Чтобы уменьшить рутину, вы добавили мета-скилл вроде refine, который автоматически дорабатывает скиллы на основе вашей обратной связи в конце каждой сессии. Теперь вы даже не читаете предложения мета-скилла, а просто смотрите результаты — всё остальное происходит как по волшебству.
Но через несколько недель вы замечаете: анализ стал поверхностным. Например, агент выдаёт шаблонные сводки и чрезмерно полагается на поверхностное сравнение фич: как-то раз именно такое поведение случайно поощрила ваша обратная связь.
- Возникает соблазн отобрать у агента автономию в части изменения собственных скиллов. Другими словами — вернуться к ручному обновлению скиллов, тратя много времени, но «обучая» агента самостоятельно.
- Можно пойти ещё дальше и вернуться к «микроменеджменту агента» — снова писать детальные промпты и отказаться от сложных скиллов, потому что их слишком тяжело поддерживать.
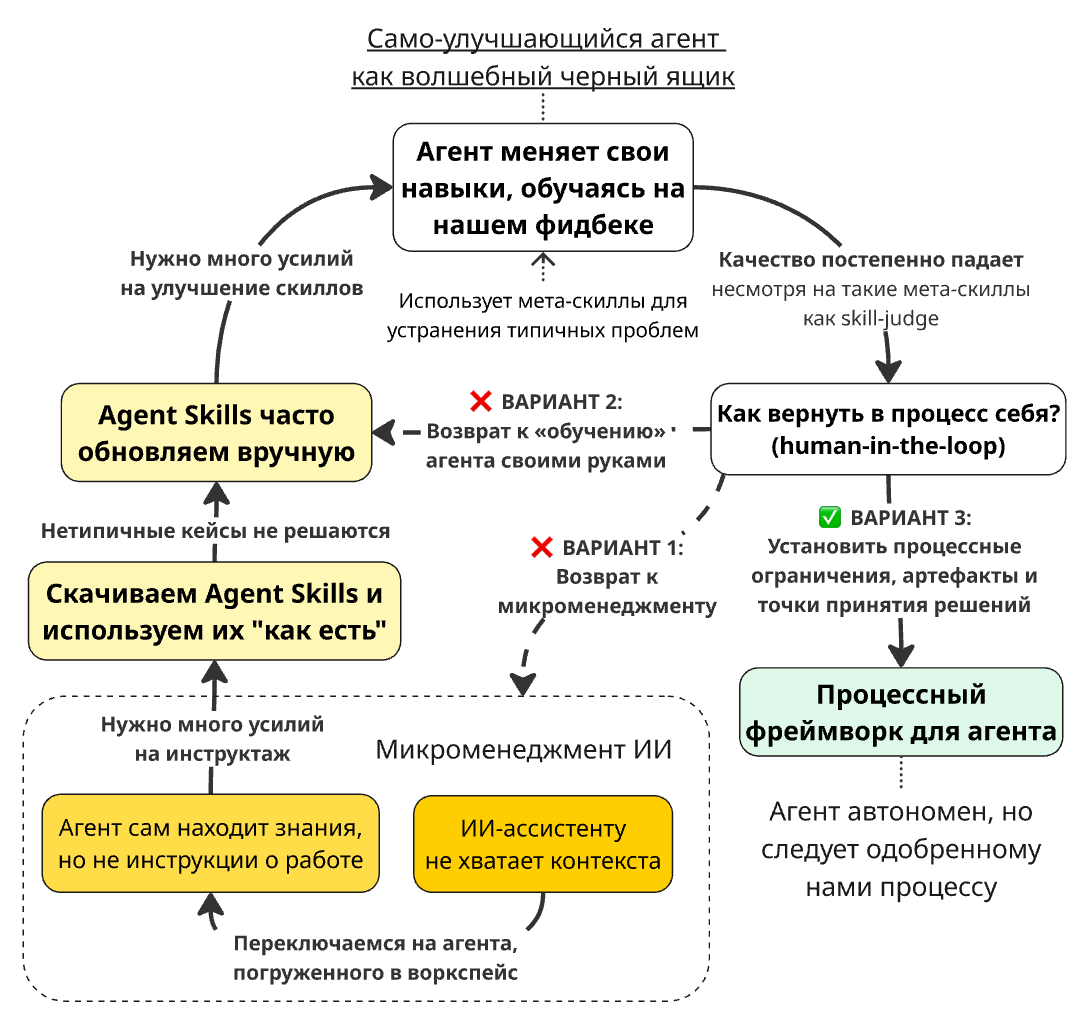
Правильный способ вернуть себя в процесс (human-in-the-loop)
Какая ситуация из до-агентного мира напоминает вышеуказанную проблему? Наиболее подходящая аналогия, на мой взгляд, — это самоуправляемая команда. Если просто дать много автономии команде, привыкшей работать под руководством менеджера или тимлида, результаты ухудшатся. И что критично — менеджер не сможет точно определить, почему они ухудшились.
Когда речь заходит о принципах организации такой команды, ничего лучше Scrum пока не придумали. Конкретные артефакты и события Скрама к агенту, конечно, неприменимы. Но:
Вот три принципа для агентов, напоминающих Scrum, простым языком (подробнее будет ниже):
- Мы позволяем агенту работать автономно в рамках процессных ограничений, заданных нами как менеджерами («скрам-мастерами»).
- Мы используем определённые контрольные точки / триггеры («события для Инспекции»), чтобы понимать решения агента и убеждаться, что результаты и рабочий процесс улучшаются («адаптируются»).
- Для этого мы используем специальные артефакты (файлы), достаточно короткие, чтобы мы, люди, могли их читать и иногда редактировать («Прозрачность артефактов»).
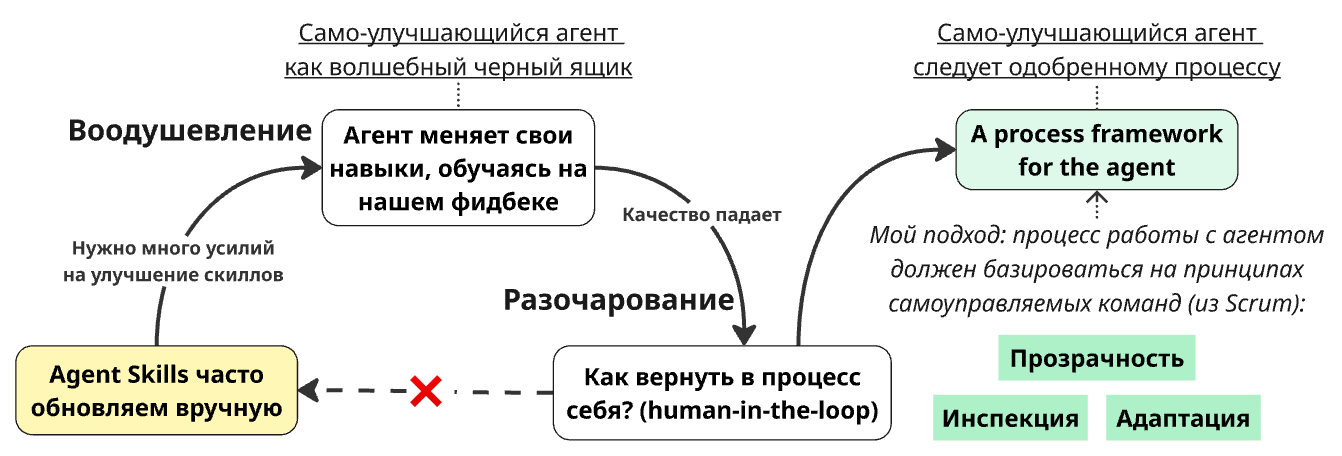
Заметьте: процессные ограничения агента — это не то же самое, что обвязка (harness) агента. Агентная обвязка — гораздо более широкое понятие: память, управление циклами, разрешения и множество других технических деталей. Помимо традиционной harness, рабочие процессы с агентом должны подчиняться принципам более высокого уровня.
Следуя аналогии со Скрамом, я бы назвал эти принципы и соответствующие практики «процессным фреймворком для агентов».
Рассмотрим конкретные практики, которые помогают мне реализовать Прозрачность, Инспекцию и Адаптацию при работе с агентами. Ваши практики могут отличаться, но базовые принципы — Прозрачность, Инспекция и Адаптация — достаточно универсальны.
1. Прозрачность
В простейших случаях прозрачность не требует специальных действий. Теоретически, вы можете прочитать все артефакты, которые создаёт агент. Но на практике нужны специальные файлы, чтобы работа была:
- прозрачной для вас,
- доступной для последующей инспекции агентом.
1.1. Таск-файлы
Чтение длинных ответов ИИ — даже в режиме diff с подсветкой последних изменений — требует слишком много усилий.
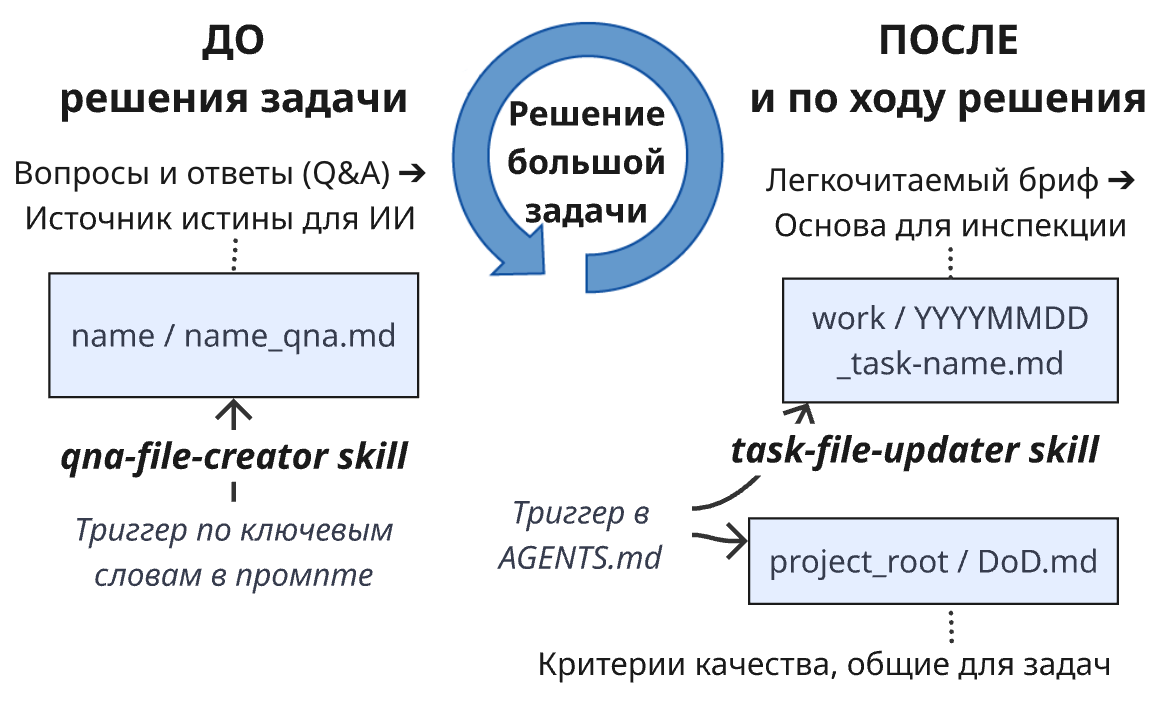
Чтобы понять, что было найдено и сделано в текущей рабочей сессии — и почему именно так, — нужно дать агенту инструкцию: сохранять краткий бриф сессии (список пунктов) в отдельный файл. Этот файл должен иметь метку даты/времени в своем имени и лежать в определённой директории проекта.
В этой статье вы или ваш агент найдёте пример организации файлов-брифов и README со списком сессий. Там это сделано для восстановления контекста агента в новой сессии. С помощью skill-creator можно превратить это в скилл, который обеспечивает прозрачность работы агента для вас.
Вот моя версия такого скилла: task-file-updater. Я предпочитаю называть единицу работы «задачей» (task), а не «сессией», хотя обычно одна сессия (чат с агентом) — это и есть одна задача.
Поначалу можно вызывать скилл task-file-updater вручную, например, фразой «сохрани таск-файл» в промпте. Но если такая прозрачность показалась полезной, таск-файл может обновляться после каждого изменения артефактов. Вот как это сделать:
- Простой способ: добавьте инструкцию вроде «After every file write or edit, invoke task-file-updater skill to create/update task file(s)» в файл AGENTS.md или CLAUDE.md — тогда эту инструкцию не нужно писать в начале каждой сессии. Это работает, но без гарантий.
- Если вы технарь и используете агентов в терминале (Claude Code, Codex CLI, Antigravity CLI), можно создать hook. В отличие от markdown-инструкций для LLM, хук срабатывает с гарантией 100% на каждое изменение артефакта (т.е. на вызовы инструментов Edit и Write).
Таск-файлы (т.е. хранимые брифы сессий) не только делают работу агента понятной для вас как менеджера. Ниже, в разделах 2.2 и 2.3, показано, как сам агент использует таск-файлы для двух типов инспекции и адаптации.
Чтение таск-файла — не самый надёжный инструмент прозрачности. Гораздо больше можно узнать о работе агента, если встроить в рабочий процесс совместное создание файла — когда вы с агентом поочередно редактируете один файл. Вот пример такого подхода:
1.2. Q&A-файлы как источник истины
Для прозрачности я также использую файлы другого типа, основанные на моём уважении к стратегии Flipped Interaction. Это файл вопросов и ответов (Q&A), который повышает прозрачность контекста для меня и моего агента. Q&A-файл создаётся интерактивно: агент изучает переданный ему контекст (который я не читал) и генерирует вопросы, а затем я отвечаю на них в файле и просто пишу в чат слово «ответил».
Зачем это нужно:
- Вопросы отражают ключевые неопределённости и точки принятия решений. Поэтому их чтение — гораздо более эффективный способ познакомиться с самыми важными деталями, чем чтение исходного контекста.
- Пассивное чтение контекста не помогает глубоко его понять и тем более запомнить. Ответы на вопросы помогают и в том, и в другом — и вы остаётесь экспертом во всём, что делает ваш агент (и вот почему это важно).
- Когда вопросы и ответы разбросаны по чатам, их невозможно находить. Например, вы можете забыть решение, принятое давно, и агент не сможет вам помочь. Даже если вы скажете «Почему так?», а не «Странно, давай откатим», агент все равно не напомнит вам о рассуждениях, стоящих за старым решением. Я сталкивался с этой ситуацией пару раз при разработке софтверного проекта по спецификации. Без Q&A-файлов это наверняка случалось чаще, но вспомнить истинные причины принятых решений я смог лишь дважды.
Как поддерживать Q&A-файлы:
- Обычно я делаю 2 или даже 3 итерации; каждая новая порция вопросов и ответов добавляется в конец Q&A-файла.
- В итоге получается файл *_qna.md, который может служить временным источником истины при создании итоговых артефактов. Это особенно полезно, если вы решите продолжить в новой сессии — чтобы избежать лишних затрат токенов или автосжатия контекста агентом.
- Для управления процессом (включая именование и формат файлов) у меня есть скилл qna-file-creator, который активируется фразой типа «задай вопросы».
Q&A-файлы закрепляют ваши ответы как контекст, сохраняющийся между сессиями. Даже после нескольких раундов самосовершенствования скиллов фокус агента остаётся привязан к вашим текущим приоритетам, а не к общим паттернам, которые скилл "зафиксировал навечно". Другими словами:
- Сами скиллы должны избегать чрезмерно конкретных деталей и предпочтений, которые быстро становятся неактуальными.
- Q&A-файлы — правильное место для "истин с меньшим временем жизни" о продукте и процессе. В отличие от скиллов, они попадают в контекст ИИ, только если вы на них сослались явно ИЛИ если вы работаете в той же папке, а инструкция искать *_qna.md включена в файл AGENTS.md.
1.3. Цели и Definition of Done
Прозрачность должна работать в обе стороны — не только для вас, но и для агента. Вот распространённая проблема: вы говорите агенту, ЧТО КОНКРЕТНО делать, но не даёте важного ОБЩЕГО контекста вашей работы. В Scrum такая непрозрачность решается двумя вещами:
- у каждого спринта есть краткий текст Sprint Goal,
- каждый инкремент проверяется по чек-листу Definition of Done (DoD, Критерии готовности).
Для агента это выглядит иначе.
Во-первых, мне нужно убедиться, что цель прозрачна для агента — независимо от того, какой промпт я ему дал. Лично для меня это критично: я люблю погружаться в детали при общении с агентами и людьми. Но в отличие от людей, агент обучен предпочитать именно детали, поэтому он думает «о, всё понятно» и сразу переходит к реализации — хотя эти детали могут противоречить общей цели.
Однако ИИ очень редко самостоятельно угадывает с целью (ЗАЧЕМ мы это делаем). Я пробовал создать универсальный скилл, который выводит "ЗАЧЕМ" из релевантного контекста в файлах проекта… но этот скилл оказался полезен, лишь когда я сузил область его применимости до конкретного проекта.
Поэтому я пришёл к простой инструкции в AGENTS.md (скилл не нужен):
"Before implementing a complex multi-step task, formulate your understanding of a broader goal, ask "Do I get it right?" and wait for the user approval or corrections."
Этот триггер срабатывает не на 100%, поэтому иногда я пишу явный запрос вроде «Сначала сформулируй своё понимание общей цели и подожди моих правок».
Во-вторых, в моём AGENTS.md есть ссылка на файл DoD.md. Этот файл Definition of Done содержит критерии качества, общие для всех задач тех типов, которые встречаются в данном проекте. Агент должен сверяться с DoD.md при самопроверке результатов.
Критерии готовности (DoD) — это не только про прозрачность. Они помогают экономить время, когда вы регулярно делаете однотипную работу. В следующем разделе обсуждаются критерии успеха для конкретной задачи. Так вот, лайфхак: если вы создадите DoD для типа задач, то критерии успеха, предлагаемые агентом для конкретной задачи, будут лучше для каждой задачи этого типа — без ваших правок.
Определять Definition of Done особенно важно для не-программистских задач (в разработке-то DoD и типичные критерии успеха хорошо известны ИИ-моделям).
 Рекомендуемые артефакты (файлы), и как они создаются/обновляются
Рекомендуемые артефакты (файлы), и как они создаются/обновляются2. Инспекция и Адаптация
Когда мы говорим об инспекции, мы имеем в виду триггеры, которые запускают адаптацию. В Скраме такими триггерами служат события (встречи). Для агента это может выглядеть следующим образом.
2.1. Критерии успеха: агент пишет, вы проверяете
Первый триггер — начало каждой задачи или группы связанных задач. В Скраме это называется спринтом. Но с агентом нужны микроспринты длительностью не более часа, ограниченные контекстным окном модели. Все задачи в микроспринте должны быть тесно связаны и направлены на одну цель.
- По моему опыту, если это девелоперский проект (AI coding), в микроспринт помещается только одна задача — поскольку много токенов сгорает при написании тестов и в цикле автоматического исправления багов агентом. Иногда этот сложный цикл приводит к разбиению задачи на несколько сессий.
- Если же цикл проще девелоперского, в одном микроспринте может быть более одной задачи.
- Однако есть неизбежные накладные расходы на старт и завершение каждой задачи, поэтому задача должна быть достаточно крупной, чтобы в токенах она стоила больше этих накладных расходов. Другими словами, не превращайте микроспринт в наноспринт 😉
Что делать в начале микроспринта? Андрей Карпати рекомендует: «Не говорите агенту, что делать, дайте ему критерии успеха и смотрите, как он работает». Вы можете пойти дальше и добавить в CLAUDE.md строку: «Define success criteria» (здесь об этом подробнее). Это даст вам черновик критериев для ревью каждый раз перед тем, как агент начнет решать задачу.
Что касается адаптации: не ленитесь читать критерии успеха и, возможно, корректировать их. Иначе агент потратит токены и ваше время, пытаясь удовлетворить неправильно сформулированные или нерелевантные критерии. Цена ошибки на этом этапе высока.
2.2. Ревью: не только читаем резюме проделанной работы
Второй триггер срабатывает в конце каждого микроспринта. Он напоминает Scrum Sprint Review — обзор проделанной работы со сбором обратной связи. С агентом отличие в том, что обратная связь обычно не собирается от вас в конце — ведь вы уже давали её по ходу работы.
Таким образом, таск-файл может содержать конкретные выводы для адаптации — а не просто бриф сессии для прозрачности. Даже если у вас нет привычки читать брифы сессий, вы обязаны просмотреть выводы, предложенные агентом. И удобно отредактировать их прямо в файле (это быстрее, чем давать ИИ фидбек на выводы в чате).
Адаптация на этом этапе может затрагивать две вещи:
- Адаптация плана работы (похоже на Scrum Sprint Review). Часто по итогам ревью создаются черновые описания следующих задач. Иногда нужно создать новые задачи или новые пункты в списке «технического долга». После вашего подтверждения всё это записывается агентом вместе с брифом сессии.
- Общий рабочий процесс. Например, здесь я описывал мета-скилл «refine» для адаптации скиллов и файла CLAUDE.md на основе анализа сессии. Или вот мой скилл такого рода — issues-recorder. С подобными скиллами обычно не нужно формулировать обратную связь по процессу самостоятельно, но предложенные агентом улучшения необходимо проверять.
Реализацию таких улучшений лучше отложить на потом (реализация описывается в следующем разделе). Но черновые решения об улучшениях должны быть сохранены в конце каждого микроспринта, причем агент не должен делать это без вашего ревью.
2.3. Ретроспектива: главное условие само-улучшений агента
Наконец, последний триггер может срабатывать по расписанию — скажем, раз в неделю или раз в месяц (в Claude это можно сделать через Dispatch). Это аналог регулярной ретроспективы в Скраме. Но для начала в качестве триггера может выступать просто ваша готовность уделить время улучшению процесса работы.
Здесь используется информация, накопленная за несколько микроспринтов, — информация о процессных проблемах, а не о конкретных задачах. Это важный аргумент в пользу создания файлов (например, таск-файлов), в которых такая информация накапливается.
Не только агент проводит анализ этой информации по триггеру. Вы тоже должны дополнить контекст агента своей обратной связью или дополнительными промптами. Если это неудобно, вы не станете этого делать. Поэтому ретроспективу стоит проводить нечасто, в удобное для вас время.
Теоретически можно избежать этого долга полностью, решая процессные проблемы в конце каждого микроспринта (сразу после ревью). Но длительное переключение внимания — это огромная когнитивная нагрузка: невозможно делать это каждый час. Более реалистично — в конце микроспринта лишь ненадолго переключиться, чтобы прочитать ключевые проблемы и предложенные агентом решения для них.
Поэтому я теперь использую собственный скилл issues-recorder вместо упомянутого выше refine. Он выполняет лишь первую часть работы refine: анализ проблем на этапе ревью сессии. Вторая часть — обновление скиллов — выполняется скиллом issues-retrospective по запросу (если бы Claude Code был моим основным агентом, я бы вызывал его по расписанию).
Нечастые ретроспективы полезнее, чем доработка процессов в конце каждой сессии, по двум причинам:
- Фокус на текущих задачах, а не отвлечение на процессные вопросы (см. выше). Та же логика стоит за командными ретроспективами в Scrum.
- Наблюдения накапливаются, пока не станут паттернами, а не случайными фактами. Проблема, замеченная один раз, может не повториться никогда. Ретроспектива — это механизм «стейджинга» (сначала накапливаем в буфере, потом выпускаем). Это гарантирует, что адаптация основана именно на повторяющихся паттернах. Для ИИ-агентов это даже важнее, чем для скрам-команд, — агенты с трудом оценивают и приоритизируют такие процессные вопросы.
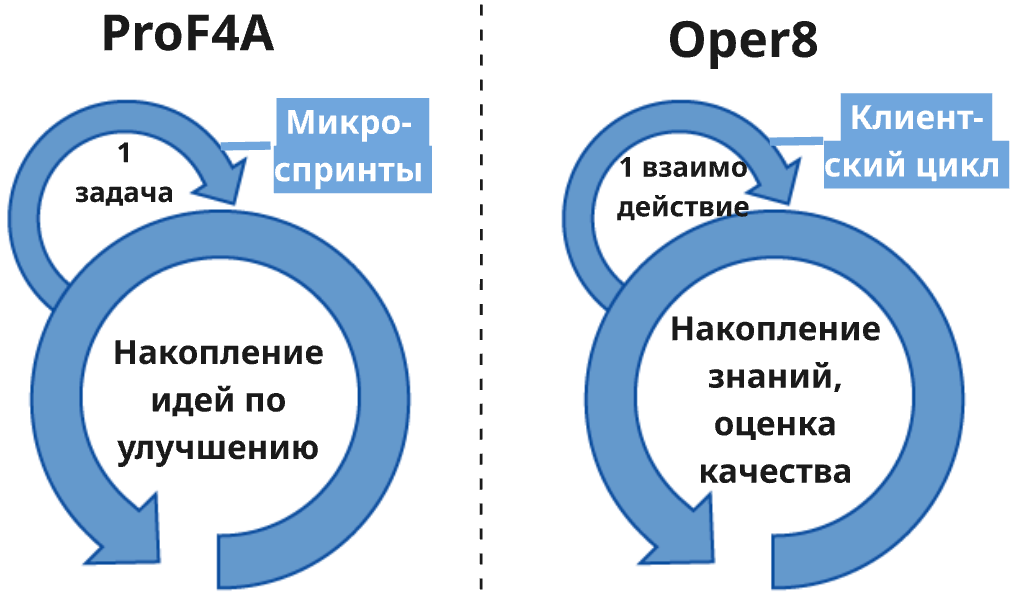
Заключение: фреймворк ProF4A и методика Oper8
Итак, в предложенном мной «процессном фреймворке для агентов» (назову его для краткости ProF4A) есть два цикла инспекции и адаптации:
- Короткий цикл по решению одной большой задачи («микроспринт»). В большинстве случаев 1 задача — это одна сессия работы агента, но ограниченность контекстного окна может потребовать нескольких сессий (в этом случае можно использовать описанный в разделе 1.1 таск-файл или просто попросить агента «написать handoff для продолжения в новой сессии» — он поймёт, что это и зачем). Если человек сразу реагирует на вопросы и предложения агента, то микроспринт занимает порядка 30–60 минут, включая ревью плана дальнейшей работы.
- Длинный цикл — ретроспективный анализ накопившихся предложений по улучшению процесса работы (не имеет отношения к конкретным целям проекта/продукта). Ретроспектива может проходить раз в неделю, раз в месяц или как вам удобно.
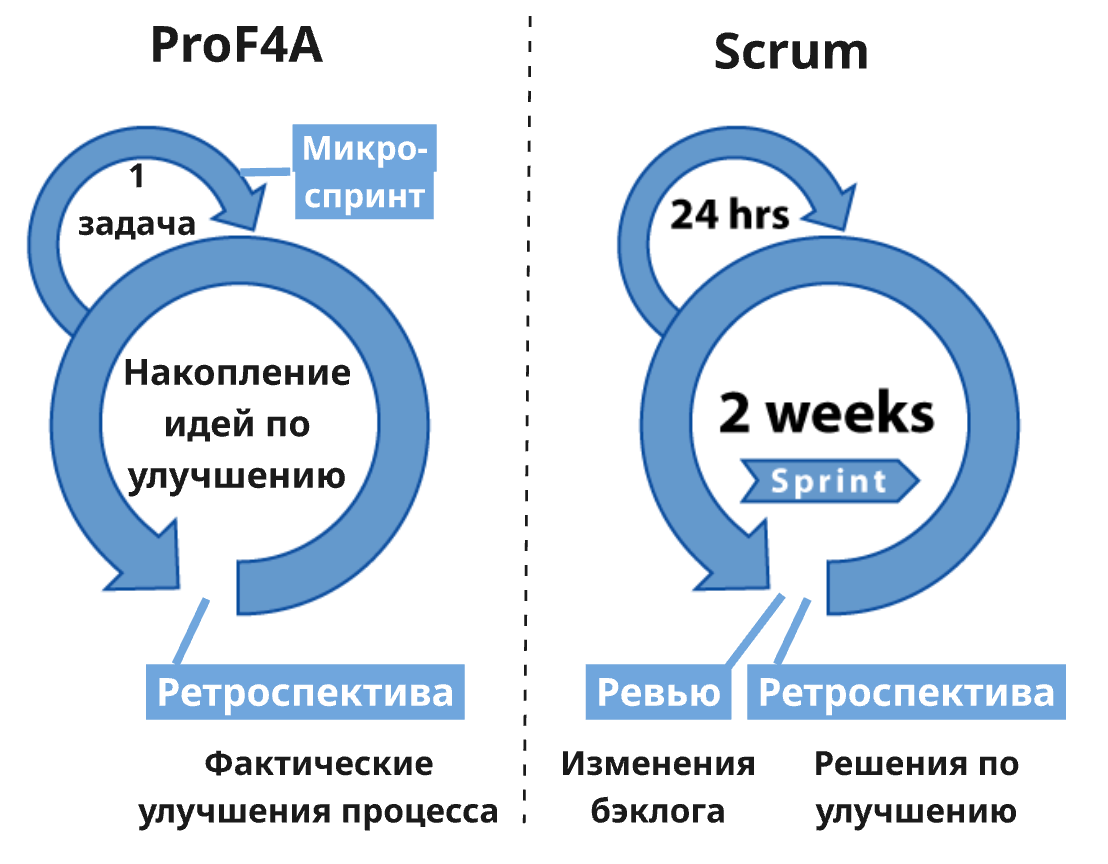
В Scrum тоже два цикла, но их смысл сильно отличается:
- Короткий цикл — это не микроспринт длительностью до часа, а один день работы; во время Daily Scrum команда инспектирует прогресс на пути к цели спринта.
- Длинный цикл — это как раз спринт, длительностью от 1 до 4 недель. Причём этот период (длительность спринта) одинакова как для адаптации плана работы над продуктом (Sprint Review), так и для процессных адаптаций (Sprint Retrospective). Scrum похож на описанный выше процесс в части ретроспективы, но в части ревью сильно отличается.
Ближе к процессному фреймворку ProF4A — методика Oper8. Она глубоко проработана авторами (книга на полсотни страниц) и протестирована на реальных кейсах. А главное — в отличие от этой статьи, Oper8 не про индивидуальную работу с агентом, а про внедрение в операционные процессы компании, в т.ч. в работу с клиентами.
В Oper8 два цикла выглядят так:
- Внешний короткий цикл — каждое действие компании и ответная реакция конкретного клиента (таких циклов обычно столько, сколько клиентов). «Действия компании» поначалу выполняются живыми сотрудниками (ИИ — лишь ассистент, предлагающий тексты/решения), но со временем автономность ИИ повышается — вплоть до уровня, когда агент работает с клиентами сам, а сотрудник лишь мониторит метрики и вмешивается при аномалиях.
- Внутренний длинный цикл — про обучение системы на основе данных, накопленных короткими циклами из пункта 1. Это уже про правила и паттерны, касающиеся всех клиентов. Аналогично вышеописанной ретроспективе с агентом, вовлечение человека (human-in-the-loop) здесь крайне важно для того, чтобы система само-улучшалась, а не просто само-обучалась.
Базовые идеи Oper8 и ProF4A похожи:
- Конкретная работа делается короткими итерациями, и результаты каждой итерации (насколько хорошо получилось + возникшие проблемы) должны запоминаться. Агенту несложно учитывать эти результаты на следующей итерации короткого цикла (при решении следующей подобной задачи в ProF4A или при следующем взаимодействии с тем же клиентом в Oper8).
- Но чтобы улучшалась система в целом, этого недостаточно. Нужен длинный цикл, где человек с ИИ совместно анализируют конкретные результаты коротких циклов и делают улучшения общего характера (процессные улучшения в ProF4A, адаптация общих правил в Oper8).